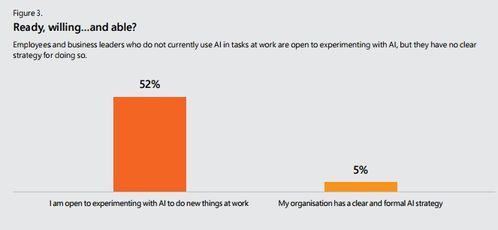
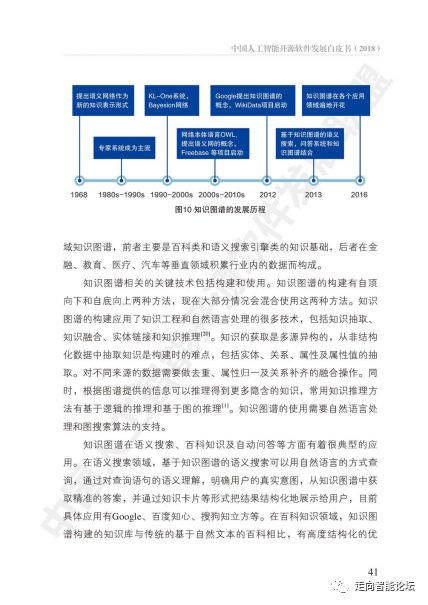
引言:智能的基石——有监督学习
有监督学习(Supervised Learning)是人工智能领域,尤其是机器学习分支中应用最广泛、最成熟的学习范式。它为计算机提供了从经验中学习的能力,其核心思想是通过对带有明确标签的历史数据进行分析,构建一个模型,使得该模型能够对新的、未见过的数据做出准确的预测或分类。在当今如火如荼的人工智能应用软件开发浪潮中,有监督学习扮演着不可或缺的“发动机”角色。
一、 核心原理:从“示例教学”到“举一反三”
有监督学习的过程,可以类比于一位老师(算法)使用一本带有标准答案(标签)的习题集(训练数据)来指导学生(模型)学习。其工作流程主要包含以下几个关键步骤:
- 数据准备:这是整个流程的基石。开发者需要收集大量高质量的、已标注的数据。例如,要开发一个猫狗图片识别应用,就需要成千上万张明确标注了“猫”或“狗”的图片。数据的数量和质量直接决定了模型性能的上限。
- 特征工程:原始数据(如一张图片的像素值、一段文本的字符)通常不能直接被算法理解。特征工程是将原始数据转化为算法能够有效处理的数值型特征的过程。例如,对于文本情感分析,特征可能是词频、词向量;对于用户画像,特征可能是年龄、浏览历史、消费金额等。
- 模型选择与训练:根据任务类型(分类或回归),选择合适的算法模型。
- 分类任务:预测离散的类别标签。常用算法包括逻辑回归、决策树、随机森林、支持向量机(SVM)以及深度神经网络(如CNN用于图像,RNN/LSTM用于文本)。
- 回归任务:预测连续的数值。常用算法包括线性回归、多项式回归、决策树回归等。
训练过程即算法不断调整模型内部参数,以最小化预测结果与真实标签之间的误差(损失函数)。
- 评估与优化:使用未参与训练的数据集(测试集)来评估模型的泛化能力,即处理新数据的能力。常用评估指标包括准确率、精确率、召回率、F1分数(分类任务)和均方误差、R²分数(回归任务)。根据评估结果,通过调整模型参数、改进特征或使用更多数据来优化模型。
- 部署与推断:将训练好的模型集成到应用程序中,接受新的输入数据,并输出预测结果,从而提供智能服务。
二、 在AI应用软件开发中的关键应用场景
有监督学习的强大预测能力,使其成为众多主流AI应用的核心驱动力:
- 计算机视觉:
- 图像分类与识别:相册自动分类、社交媒体内容审核、工业质检(识别缺陷产品)。
- 目标检测:自动驾驶中的行人车辆识别、安防监控中的异常行为检测。
- 人脸识别:手机解锁、支付验证、门禁系统。
- 自然语言处理:
- 文本分类:新闻自动归类、垃圾邮件过滤、情感分析(分析用户评论是正面还是负面)。
- 序列标注:命名实体识别(从病历中提取疾病、药品名)、词性标注。
- 机器翻译:谷歌翻译、DeepL等工具的核心技术。
- 语音技术:
- 语音识别:智能音箱(如小爱同学、天猫精灵)、语音输入法、会议转录。
- 说话人识别:声纹锁、个性化语音助手。
- 推荐系统:
- 电商平台(如淘宝、亚马逊)的“猜你喜欢”、视频网站(如Netflix、YouTube)的个性化内容推荐,均基于用户历史行为(点击、购买、观看)的监督学习模型。
- 金融与风控:
- 信用评分:根据用户的收入、负债、历史信用记录预测贷款违约风险。
- 欺诈检测:实时分析交易模式,识别异常信用卡交易。
三、 开发实践:挑战与最佳实践
在软件开发中集成有监督学习模型并非易事,开发者需应对以下挑战并遵循最佳实践:
主要挑战:
- 数据依赖与瓶颈:获取大量高质量标注数据成本高昂、周期长,且可能存在标注错误和偏见。
- 模型泛化与过拟合:模型在训练集上表现完美,但在真实场景中表现不佳,即“过拟合”。
- 概念漂移:现实世界的数据分布可能随时间变化(如用户兴趣迁移),导致模型性能下降。
- 计算资源与延迟:复杂模型(尤其是深度学习)训练和推断需要大量算力,可能影响应用响应速度。
最佳实践指南:
1. 数据为王,质量优先:投入资源构建干净、全面、无偏的数据集。可采用数据增强技术(如图像旋转、添加噪声)来有限扩充数据。
2. 构建迭代式开发流程:采用MLOps理念,将数据准备、模型训练、评估、部署和监控自动化、流水线化,实现模型的持续迭代和快速交付。
3. 重视模型解释性与公平性:特别是在金融、医疗等高风险领域,需要理解模型做出决策的依据(使用LIME、SHAP等工具),并检测和修正模型可能存在的歧视性偏见。
4. 从简单模型开始:不要盲目追求复杂的深度学习模型。通常,逻辑回归、决策树等简单模型在特征工程得当的情况下,既能提供良好性能,又更易于解释和部署。
5. 云端部署与优化:利用AWS SageMaker、Google AI Platform、Azure Machine Learning等云平台的服务,简化模型部署、版本管理和弹性伸缩,并考虑使用模型压缩、量化等技术优化推断速度。
###
有监督学习作为人工智能的基石技术,已经并将继续深刻改变我们开发软件的方式。它使应用程序具备了“预测”和“认知”的智能。对于AI应用软件开发者而言,深入理解其原理,熟练掌握从数据到部署的全流程,并清醒认识其局限性与伦理边界,是构建成功、可靠、负责任的智能产品的关键。随着自动化机器学习(AutoML)、小样本学习等技术的发展,有监督学习的门槛正在降低,其应用前景将更加广阔和深远。